
Als Programmierer müssen Sie möglicherweise eine Reihe von PDF Dateien verarbeiten und Text daraus extrahieren. Die Textextraktion aus PDF kann für verschiedene Zwecke erforderlich sein, z. B. für die Textanalyse. In diesem Artikel zeigen wir, wie einfach es ist, Text aus einer PDF-Datei in Python zu extrahieren. Außerdem erfahren Sie, wie Sie Text extrahieren und in einer TXT-Datei speichern.
- Python Bibliothek zum Extrahieren von Text aus PDF Dateien
- So extrahieren Sie Text aus einem PDF
- Textextraktion aus einem PDF in Python
Python Bibliothek zum Extrahieren von Text aus PDF – kostenloser Download
Aspose.Words for Python ist eine erstaunliche Bibliothek, mit der Sie Textdokumente nahtlos erstellen und verarbeiten können. Sie können die Dokumente gängiger Formate wie DOC, DOCX und PDF bearbeiten. Wir werden diese Bibliothek verwenden, um eine Textextraktion für unsere PDF Dateien durchzuführen. Sie können die Bibliothek von PyPI mit dem folgenden Pip-Befehl installieren.
> pip install aspose-words
So extrahieren Sie Text aus PDF in Python
Aspose.Words for Python hat die PDF-Textextraktion extrem einfach gemacht, indem die komplexen Operationen vor dem Benutzer verborgen wurden. Sie müssen nur die PDF-Datei laden und den extrahierten Text speichern. Die folgenden Schritte veranschaulichen das Extrahieren von Text aus einer PDF-Datei mit Aspose.Words for Python.
- Laden Sie die PDF-Datei vom gewünschten Ort.
- Extrahieren und speichern Sie den Text in einer TXT-Datei.
Und das ist alles. Anschließend können Sie die .txt-Datei verarbeiten und den aus der PDF-Datei extrahierten Klartext bearbeiten.
Sehen wir uns nun an, wie Text aus einer PDF-Datei programmgesteuert in Python extrahiert wird.
Textextraktion aus PDF in Python
Im Folgenden sind die Schritte zusammen mit Klassen und Methoden für die PDF-Textextraktion in Python aufgeführt.
- Laden Sie die PDF-Datei mit der Document Klasse.
- Extrahieren Sie Text aus PDF in eine .txt-Datei mit der Methode Document.save(fileName).
Das folgende Codebeispiel zeigt die Textextraktion aus einer PDF-Datei in Python.
# Importieren Sie Aspose.Words für das Python-Modul
import aspose.words as aw
# PDF-Datei laden
pdf = aw.Document("file.pdf")
# Extrahieren und speichern Sie Text in einer TXT-Datei
pdf.save("extracted-text.txt")
Der folgende Screenshot zeigt die Eingabe-PDF-Datei, die wir für die Textextraktion verwendet haben.

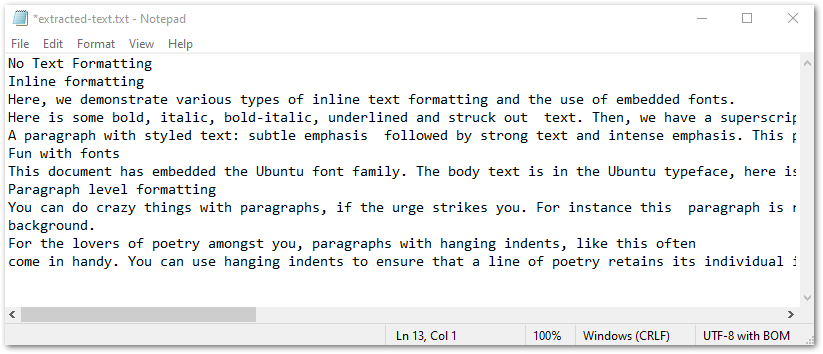
Der folgende Screenshot zeigt den extrahierten Text in einer TXT-Datei.
PDF Text Extractor for Python – Holen Sie sich eine kostenlose Lizenz
Sie können eine kostenlose temporäre Lizenz zum Extrahieren von Text aus PDF ohne Evaluierungseinschränkungen erhalten.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie Text aus PDF Dateien in Python extrahieren. Sie haben gesehen, wie einfach und schnell Sie Text aus einer PDF-Datei extrahieren und programmgesteuert in einer TXT-Datei speichern können. Jetzt können Sie die Textextraktion für einen Stapel von PDF Dateien in Ihren Python-Anwendungen implementieren.
Erkunden Sie den PDF-Textextraktor von Aspose für Python
Weitere Funktionen von Aspose.Words for Python können Sie mithilfe der Dokumentation erkunden. Falls Sie Fragen haben, können Sie uns diese gerne über unser Forum mitteilen.