
En tant que programmeur, vous devrez peut-être traiter un tas de fichiers PDF et en extraire du texte. L’extraction de texte à partir d’un PDF peut être nécessaire à diverses fins telles que l’analyse de texte. Dans cet article, nous allons montrer à quel point il est facile d’extraire du texte d’un fichier PDF en Python. De plus, vous saurez comment extraire du texte et l’enregistrer dans un fichier TXT.
- Bibliothèque Python pour extraire du texte à partir de fichiers PDF
- Comment extraire du texte d’un PDF
- Extraction de texte d’un PDF en Python
Bibliothèque Python pour extraire du texte d’un PDF - Téléchargement gratuit
Aspose.Words for Python est une bibliothèque étonnante qui vous permet de créer et de traiter des documents texte de manière transparente. Vous pouvez manipuler les documents de formats populaires tels que DOC, DOCX et PDF. Nous allons utiliser cette bibliothèque pour effectuer une extraction de texte sur nos fichiers PDF. Vous pouvez installer la bibliothèque à partir de PyPI à l’aide de la commande pip suivante.
> pip install aspose-words
Comment extraire du texte d’un PDF en Python
Aspose.Words for Python a rendu l’extraction de texte PDF extrêmement facile en cachant les opérations complexes à l’utilisateur. Il vous suffit de charger le fichier PDF et d’enregistrer le texte extrait. Les étapes suivantes montrent comment extraire du texte d’un PDF à l’aide de Aspose.Words for Python.
- Chargez le fichier PDF à partir de l’emplacement souhaité.
- Extrayez et enregistrez le texte dans un fichier .txt.
Et c’est tout. Vous pouvez ensuite traiter le fichier .txt et manipuler le texte brut extrait du PDF.
Voyons maintenant comment extraire du texte d’un PDF par programme en Python.
Extraction de texte de PDF en Python
Voici les étapes ainsi que les classes et les méthodes d’extraction de texte PDF en Python.
- Chargez le fichier PDF à l’aide de la classe Document.
- Extrayez le texte d’un PDF dans un fichier .txt à l’aide de la méthode Document.save(fileName).
L’exemple de code suivant montre l’extraction de texte d’un fichier PDF en Python.
# Importer Aspose.Words pour le module Python
import aspose.words as aw
# Charger le fichier PDF
pdf = aw.Document("file.pdf")
# Extraire et enregistrer du texte dans un fichier TXT
pdf.save("extracted-text.txt")
La capture d’écran suivante montre le fichier PDF d’entrée que nous avons utilisé pour l’extraction de texte.

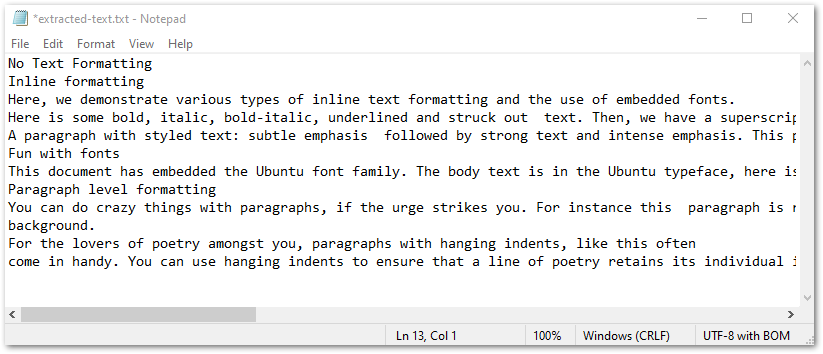
La capture d’écran suivante montre le texte extrait dans un fichier TXT.
Extracteur de texte PDF pour Python - Obtenez une licence gratuite
Vous pouvez obtenir une licence temporaire gratuite pour extraire du texte d’un PDF sans limitation d’évaluation.
Conclusion
Dans cet article, vous avez appris à extraire du texte de fichiers PDF en Python. Vous avez vu avec quelle facilité et quelle rapidité vous pouvez extraire du texte d’un PDF et l’enregistrer dans un fichier TXT par programme. Désormais, vous pouvez implémenter l’extraction de texte pour un lot de fichiers PDF dans vos applications Python.
Explorez l’extracteur de texte PDF d’Aspose pour Python
Vous pouvez explorer d’autres fonctionnalités d’Aspose.Words for Python en utilisant la documentation. Si vous avez des questions, n’hésitez pas à nous en faire part via notre forum.