
プログラマーとして、一連の PDF ファイルを処理し、それらからテキストを抽出する必要がある場合があります。 PDF からのテキスト抽出は、テキスト分析などのさまざまな目的で必要になる場合があります。この記事では、Python で PDF ファイルからテキストを抽出するのがいかに簡単かを説明します。さらに、テキストを抽出して TXT ファイルに保存する方法を知るようになります。
PDF からテキストを抽出する Python ライブラリ - 無料ダウンロード
Aspose.Words for Python は、テキスト ドキュメントをシームレスに作成および処理できる素晴らしいライブラリです。 DOC、DOCX、PDF などの一般的な形式のドキュメントを操作できます。このライブラリを使用して、PDF ファイルのテキスト抽出を実行します。次の pip コマンドを使用して、PyPI からライブラリをインストールできます。
> pip install aspose-words
Python で PDF からテキストを抽出する方法
Aspose.Words for Python では、複雑な操作をユーザーから隠すことで、PDF テキストの抽出が非常に簡単になりました。 PDF ファイルを読み込んで、抽出したテキストを保存するだけです。次の手順は、Aspose.Words for Python を使用して PDF からテキストを抽出する方法を示しています。
- 目的の場所から PDF ファイルを読み込みます。
- テキストを抽出して .txt ファイルに保存します。
それだけです。その後、.txt ファイルを処理し、PDF から抽出されたプレーン テキストを操作できます。
それでは、Python でプログラムによって PDF からテキストを抽出する方法を見てみましょう。
Python での PDF からのテキスト抽出
以下は、Python で PDF テキストを抽出するためのクラスとメソッドに沿った手順です。
- Document クラスを使用して PDF ファイルを読み込みます。
- Document.save(fileName) メソッドを使用して、PDF から .txt ファイルにテキストを抽出します。
次のコード サンプルは、Python での PDF ファイルからのテキスト抽出を示しています。
# Aspose.Words for Python モジュールのインポート
import aspose.words as aw
# PDFファイルを読み込む
pdf = aw.Document("file.pdf")
# テキストを抽出して TXT ファイルに保存する
pdf.save("extracted-text.txt")
次のスクリーンショットは、テキスト抽出に使用した入力 PDF ファイルを示しています。

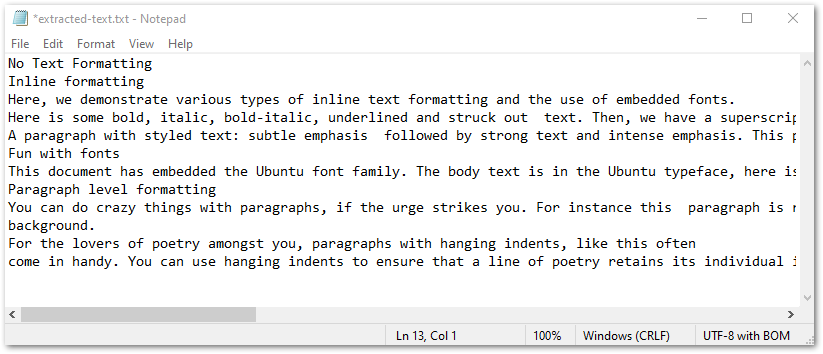
次のスクリーンショットは、TXT ファイルで抽出されたテキストを示しています。
Python 用 PDF テキスト エクストラクタ - 無料ライセンスを取得
無料の一時ライセンス を取得して、評価制限なしで PDF からテキストを抽出できます。
結論
この記事では、Python で PDF ファイルからテキストを抽出する方法を学びました。 PDF からテキストを抽出し、それをプログラムで TXT ファイルに保存することがいかに簡単かつ迅速にできるかを見てきました。これで、Python アプリケーションで PDF ファイルのバッチのテキスト抽出を実装できるようになりました。
Python 用の Aspose の PDF テキスト エクストラクタを調べる
ドキュメント を使用して、Aspose.Words for Python の他の機能を調べることができます。ご不明な点がございましたら、フォーラム からお気軽にお問い合わせください。