
프로그래머는 많은 PDF 파일을 처리하고 그 파일에서 텍스트를 추출해야 할 수 있습니다. PDF에서 텍스트 추출은 텍스트 분석과 같은 다양한 목적을 위해 필요할 수 있습니다. 이 기사에서는 Python에서 PDF 파일에서 텍스트를 추출하는 것이 얼마나 쉬운지 보여줍니다. 또한 텍스트를 추출하고 TXT 파일로 저장하는 방법을 알게 될 것입니다.
PDF에서 텍스트를 추출하는 Python 라이브러리 - 무료 다운로드
Aspose.Words for Python은 텍스트 문서를 원활하게 만들고 처리할 수 있는 놀라운 라이브러리입니다. DOC, DOCX 및 PDF와 같은 널리 사용되는 형식의 문서를 조작할 수 있습니다. 이 라이브러리를 사용하여 PDF 파일에서 텍스트 추출을 수행할 것입니다. 다음 pip 명령을 사용하여 PyPI에서 라이브러리를 설치할 수 있습니다.
> pip install aspose-words
Python에서 PDF에서 텍스트를 추출하는 방법
Aspose.Words for Python은 복잡한 작업을 사용자에게 숨김으로써 PDF 텍스트 추출을 매우 쉽게 만들었습니다. PDF 파일을 로드하고 추출된 텍스트를 저장하기만 하면 됩니다. 다음 단계는 Python용 Aspose.Words를 사용하여 PDF에서 텍스트를 추출하는 방법을 보여줍니다.
- 원하는 위치에서 PDF 파일을 로드합니다.
- 텍스트를 추출하여 .txt 파일로 저장합니다.
그리고 그게 전부입니다. 그런 다음 .txt 파일을 처리하고 PDF에서 추출한 일반 텍스트를 조작할 수 있습니다.
이제 Python에서 프로그래밍 방식으로 PDF에서 텍스트를 추출하는 방법을 살펴보겠습니다.
Python의 PDF에서 텍스트 추출
다음은 Python에서 PDF 텍스트 추출을 위한 클래스 및 메서드와 함께 단계입니다.
- Document 클래스를 사용하여 PDF 파일을 로드합니다.
- Document.save(fileName) 메서드를 사용하여 PDF에서 .txt 파일로 텍스트를 추출합니다.
다음 코드 샘플은 Python의 PDF 파일에서 텍스트 추출을 보여줍니다.
# Python 모듈용 Aspose.Words 가져오기
import aspose.words as aw
# PDF 파일 로드
pdf = aw.Document("file.pdf")
# TXT 파일에서 텍스트 추출 및 저장
pdf.save("extracted-text.txt")
다음 스크린샷은 텍스트 추출에 사용한 입력 PDF 파일을 보여줍니다.

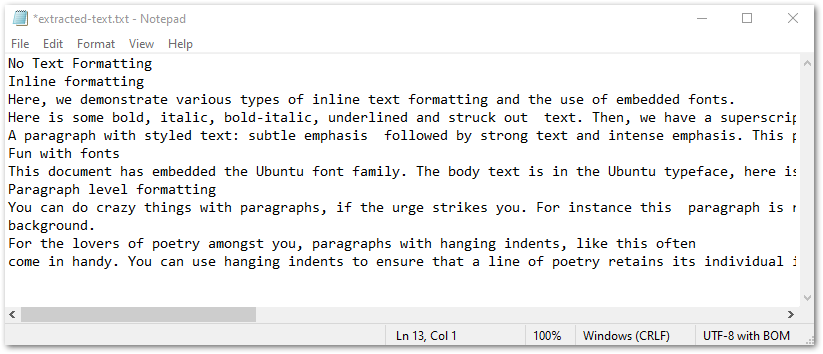
다음 스크린샷은 TXT 파일에서 추출된 텍스트를 보여줍니다.
Python용 PDF 텍스트 추출기 - 무료 라이선스 받기
평가 제한 없이 PDF에서 텍스트를 추출하기 위해 무료 임시 라이센스를 얻을 수 있습니다.
결론
이 기사에서는 Python에서 PDF 파일에서 텍스트를 추출하는 방법을 배웠습니다. PDF에서 텍스트를 추출하고 프로그래밍 방식으로 TXT 파일에 저장할 수 있는 방법을 쉽고 빠르게 살펴보았습니다. 이제 Python 애플리케이션에서 PDF 파일 배치에 대한 텍스트 추출을 구현할 수 있습니다.
Aspose의 Python용 PDF 텍스트 추출기 살펴보기
문서를 사용하여 Python용 Aspose.Words의 다른 기능을 탐색할 수 있습니다. 질문이 있는 경우 포럼을 통해 언제든지 알려주십시오.