
Tệp PDF là một trong những tài liệu kinh doanh phổ biến nhất. Trong một số trường hợp nhất định, chúng tôi có thể cần đọc các tài liệu PDF được quét theo chương trình. Khó khăn trong việc trích xuất văn bản từ các tệp PDF được quét đã dẫn đến việc phát triển các công cụ giúp đọc và truy xuất văn bản từ các tài liệu PDF đó dễ dàng hơn. Tùy thuộc vào nội dung tài liệu của bạn, việc trích xuất văn bản từ tệp PDF có thể hữu ích vì một số lý do. Trong bài viết này, chúng ta sẽ tìm hiểu cách OCR tài liệu PDF và Trích xuất văn bản từ PDF trong C#.
Các chủ đề sau sẽ được đề cập trong bài viết này:
- API OCR PDF sang văn bản C#
- OCR PDF và Trích xuất văn bản từ PDF
- Thực hiện OCR trên PDF và lưu văn bản
- OCR PDF sang tệp Word
- OCR PDF sang JSON
OCR PDF sang văn bản C# API
Chúng tôi sẽ sử dụng API Aspose.OCR for .NET để thực hiện OCR trên tài liệu PDF. Nó có thể nhận dạng hình ảnh được quét, ảnh trên điện thoại thông minh, ảnh chụp màn hình và các vùng của hình ảnh. API trả về kết quả văn bản được nhận dạng ở các định dạng trao đổi dữ liệu và tài liệu phổ biến nhất. Ngoài việc chuyển đổi hình ảnh thành văn bản, API cũng có thể tạo các tệp PDF có thể tìm kiếm dựa trên các bản quét. Hơn nữa, nó có khả năng tự động sửa lỗi chính tả trong các văn bản được nhận dạng.
API cung cấp lớp AsposeOcr cung cấp các phương thức khác nhau để thực hiện các thao tác OCR. Nó cung cấp phương pháp RecognizePdf(string, DocumentRecognitionSettings) để nhận dạng văn bản từ tài liệu PDF được cung cấp. Lớp DocumentRecognitionSettings của API cung cấp các cài đặt cho quy trình nhận dạng PDF. Lớp RecognitionResult biểu thị kết quả nhận dạng hình ảnh.
Vui lòng tải xuống tệp DLL của API hoặc cài đặt nó bằng NuGet.
PM> Install-Package Aspose.OCR
OCR PDF và trích xuất văn bản từ PDF trong C#
Chúng tôi có thể thực hiện OCR trên tài liệu PDF và trích xuất văn bản được nhận dạng bằng cách thực hiện theo các bước dưới đây:
- Đầu tiên, tạo một thể hiện của lớp AsposeOcr.
- Tiếp theo, khởi tạo một đối tượng của lớp DocumentRecognitionSettings.
- Sau đó, chỉ định ngôn ngữ sẽ được sử dụng cho OCR.
- Sau đó, lấy RecognitionResult bằng cách gọi phương thức RecognizePdf(). Nó lấy đường dẫn hình ảnh và đối tượng DocumentRecognitionSettings làm đối số.
- Cuối cùng, lặp qua danh sách RecognitionResult và hiển thị văn bản đã xác định.
Mã mẫu sau đây cho biết cách OCR tài liệu PDF và trích xuất văn bản được nhận dạng trong C#.
// Ví dụ mã này trình bày cách OCR tài liệu PDF và trích xuất văn bản được nhận dạng.
// Khởi tạo động cơ PCR
AsposeOcr recognitionEngine = new AsposeOcr();
// Khởi tạo cài đặt nhận dạng
DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings();
// Chỉ định ngôn ngữ cho OCR. Đa ngôn ngữ theo mặc định
recognitionSettings.Language = Language.Eng;
// Nhận dạng văn bản từ PDF
List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings);
// Hiển thị văn bản được nhận dạng
foreach (RecognitionResult result in results)
{
Console.WriteLine(result.RecognitionText);
}
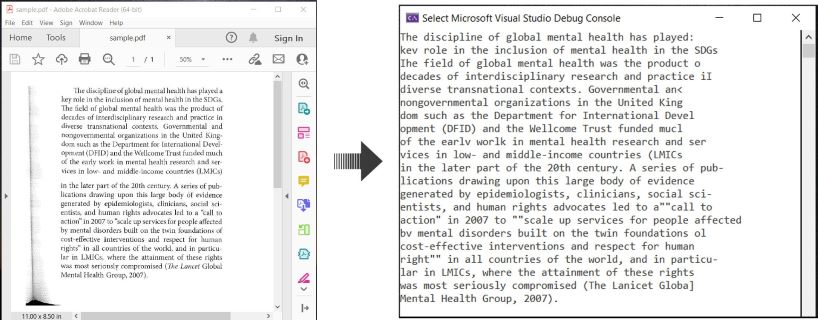
OCR PDF và trích xuất văn bản từ PDF trong C#
Thực hiện OCR trên PDF và Lưu văn bản trong C#
Chúng tôi có thể thực hiện OCR trên tài liệu PDF và lưu văn bản được nhận dạng bằng cách làm theo các bước dưới đây:
- Đầu tiên, tạo một thể hiện của lớp AsposeOcr.
- Tiếp theo, khởi tạo một đối tượng của lớp DocumentRecognitionSettings.
- Sau đó, chỉ định ngôn ngữ sẽ được sử dụng cho OCR.
- Sau đó, gọi phương thức RecognizePdf() để lấy RecognitionResult. Nó lấy đường dẫn hình ảnh và đối tượng DocumentRecognitionSettings làm đối số.
- Cuối cùng, lưu văn bản bằng phương thức SaveMultipageDocument(). Nó lấy đường dẫn tệp đầu ra, đối tượng SaveFormat và RecognitionResult làm đối số.
Mã mẫu sau đây cho biết cách OCR tài liệu PDF và lưu văn bản được nhận dạng trong C#.
// Ví dụ mã này trình bày cách OCR tài liệu PDF và trích xuất văn bản được nhận dạng.
// Khởi tạo động cơ PCR
AsposeOcr recognitionEngine = new AsposeOcr();
// Khởi tạo cài đặt nhận dạng
DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings();
// Chỉ định ngôn ngữ cho OCR. Đa ngôn ngữ theo mặc định
recognitionSettings.Language = Language.Eng;
// Nhận dạng văn bản từ PDF
List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings);
// Lưu văn bản được nhận dạng
AsposeOcr.SaveMultipageDocument("C:\\Files\\OCR_result.txt", SaveFormat.Text, results);

Thực hiện OCR trên PDF và Lưu văn bản trong C#
OCR PDF và Chuyển đổi PDF được quét thành Word trong C#
Chúng tôi có thể thực hiện OCR trên các tài liệu PDF được quét và lưu văn bản được nhận dạng trong tài liệu Word bằng cách làm theo các bước đã đề cập trước đó. Tuy nhiên, chúng ta chỉ cần chỉ định SaveFormat.Docx ở bước cuối cùng.
Mã mẫu sau đây cho biết cách OCR PDF và lưu văn bản được nhận dạng dưới dạng tài liệu Word trong C#.
// Ví dụ mã này trình bày cách OCR tài liệu PDF và lưu văn bản được nhận dạng dưới dạng DOCX.
// Khởi tạo động cơ PCR
AsposeOcr recognitionEngine = new AsposeOcr();
// Khởi tạo cài đặt nhận dạng
DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings();
// Chỉ định ngôn ngữ cho OCR. Đa ngôn ngữ theo mặc định
recognitionSettings.Language = Language.Eng;
// Nhận dạng văn bản từ PDF
List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings);
// Lưu văn bản được nhận dạng dưới dạng DOCX
AsposeOcr.SaveMultipageDocument("C:\\Files\\OCR_result.docx", SaveFormat.Docx, results);
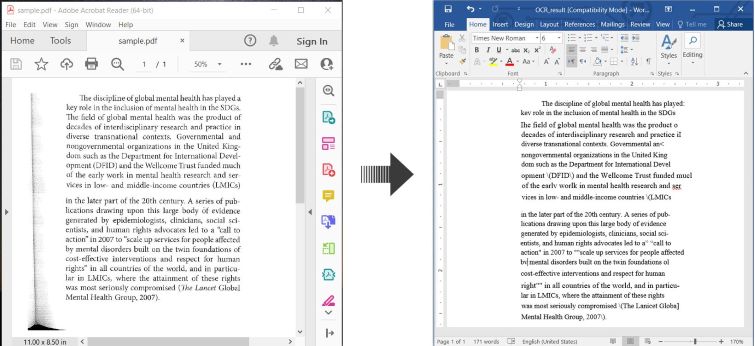
OCR PDF và Chuyển đổi PDF được quét thành Word trong C#
OCR PDF và Chuyển đổi PDF sang JSON trong C#
Chúng tôi có thể thực hiện OCR trên tài liệu PDF và lưu văn bản được nhận dạng trong tệp JSON bằng cách làm theo các bước được đề cập trước đó. Tuy nhiên, chúng ta chỉ cần chỉ định SaveFormat.Json ở bước cuối cùng.
Mã mẫu sau đây cho biết cách OCR PDF và lưu văn bản được nhận dạng dưới dạng tệp JSON trong C#.
// Ví dụ mã này trình bày cách OCR tài liệu PDF và lưu văn bản được nhận dạng dưới dạng JSON.
// Khởi tạo động cơ PCR
AsposeOcr recognitionEngine = new AsposeOcr();
// Khởi tạo cài đặt nhận dạng
DocumentRecognitionSettings recognitionSettings = new DocumentRecognitionSettings();
// Chỉ định ngôn ngữ cho OCR. Đa ngôn ngữ theo mặc định
recognitionSettings.Language = Language.Eng;
// Nhận dạng văn bản từ PDF
List<RecognitionResult> results = recognitionEngine.RecognizePdf("C:\\Files\\sample.pdf", recognitionSettings);
// Lưu văn bản được nhận dạng dưới dạng JSON
AsposeOcr.SaveMultipageDocument("C:\\Files\\OCR_result.json", SaveFormat.Json, results);
Nhận giấy phép đánh giá miễn phí
Bạn có thể nhận giấy phép tạm thời miễn phí để dùng thử thư viện mà không bị giới hạn đánh giá.
Sự kết luận
Trong bài viết này, chúng ta đã học cách thực hiện OCR trên tài liệu PDF và trích xuất văn bản từ PDF trong C#. Chúng tôi cũng đã xem cách lưu văn bản được nhận dạng dưới dạng tệp TXT, DOCX và JSON. Ngoài ra, bạn có thể tìm hiểu thêm về Aspose.OCR for .NET API bằng cách sử dụng tài liệu. Trong trường hợp có bất kỳ sự mơ hồ nào, vui lòng liên hệ với chúng tôi trên diễn đàn của chúng tôi.